Extractors are services that run silently alongside Clowder. They can be configured to wait for specific file types to be uploaded into Clowder, and automatically execute scripts and processing on those files to extract metadata or generate new files.
Setting up a development environment
In order to develop and test an extractor, it's useful to have a local instance of Clowder running that you can test against. This will allow you to upload target files to trigger your extractor, and verify any outputs are being submitted back into Clowder correctly.
Start a local Clowder instance
The easiest way to get a local Clowder instance up and running is via Docker. We have created a docker image with the full Clowder stack already installed:
- Java (to run the Clowder application itself)
- MongoDB (underlying database storage)
- RabbitMQ (message bus for communication between Clowder and extractors)
- Clowder itself
It's possible to install these elements individually, but unless you want to pursue Clowder development this is unnecessary.
- Install Docker and download our docker-compose.yml file from GitHub. This file tells Docker how to fetch and start the component containers for Clowder and its dependencies.
- From a docker-aware terminal, go to the directory where you put the .yml file and run
docker-compose up. This should start Clowder and its components. - Now you need to determine which IP address Docker is running on.
- Docker's Networking documentation shows how to use
docker network lsandifconfigto determine Docker's IP address. - Older installations that use docker-machine may need to use
docker-machine ip.
- Docker's Networking documentation shows how to use
- You should be able to now access Clowder at
<dockerIP>:9000.
You can also access the RabbitMQ management console at<dockerIP>:15672. - Finally, sign up for a local account in Clowder. Because we have not configured an email server, no confirmation email will be sent - however we can get the confirmation URL from the Clowder logs:
docker psto list running Docker containersdocker logs <clowder container name>to see the logs for your Clowder container- Look for a block of HTML in the log that is the body of the unsent email:
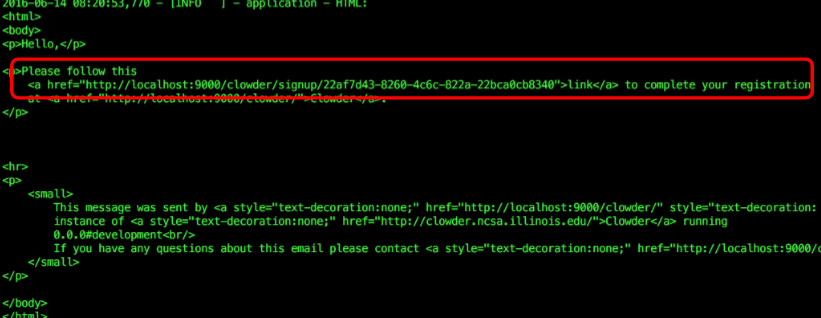
- Copy the link into your browser to activate your account. For example in the screenshot above you would visit:
http://localhost:9000/clowder/signup/22af7d43-8260-4c6c-822a-22bca0cb8340
Install pyClowder 2
Writing an extractor
Extractor events
Extractors use the RabbitMQ message bus to communicate with Clowder instances. Queues are created for each extractor, and the queue bindings filter the types of Clowder event messages the extractor is notified about. The following non-exhaustive list of events exist in Clowder (messages begin with an asterisk because the exchange name is not required to be 'clowder'):
| message type | trigger event | message payload | examples |
|---|---|---|---|
| *.file.# | when any file is uploaded |
| clowder.file.image.png clowder.file.text.csv clowder.file.application.json |
*.file.image.# *.file.text.# ... | when any file of the given MIME type is uploaded (this is just a more specific matching) |
| see above |
| *.dataset.file.added | when a file is added to a dataset |
| clowder.dataset.file.added |
| *.dataset.file.removed | when a file is removed from a dataset |
| clowder.dataset.file.removed |
| *.metadata.added | when metadata is added to a file or dataset |
| clowder.metadata.added |
| *.metadata.removed | when metadata is removed from a file or dataset |
| clowder.metadata.removed |
common requirements
sudo -s
export RABBITMQ_URL="amqp://guest:guest@localhost:5672/%2F"
export EXTRACTORS_HOME="/home/clowder"
apt-get -y install git python-pip
pip install pika requests
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/pyclowder.git
chown -R clowder.users pyclowder
opencv
apt-get -y install python-opencv opencv-data
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/extractors-cv.git
for x in opencv-closeups opencv-eyes opencv-faces opencv-profiles; do
ln -s ${EXTRACTORS_HOME}/pyclowder/pyclowder ${EXTRACTORS_HOME}/extractors-cv/opencv/$x
sed -i -e "s#rabbitmqURL = .*#rabbitmqURL = '${RABBITMQ_URL}'#" \
-e "s#/usr/local/share/OpenCV#/usr/share/opencv#" ${EXTRACTORS_HOME}/extractors-cv/opencv/$x/config.py
cp ${EXTRACTORS_HOME}/extractors-cv/opencv/$x/*.conf /etc/init
done
chown -R clowder.users extractors-cv
ocr
apt-get -y install tesseract-ocr
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/extractors-cv.git
ln -s ${EXTRACTORS_HOME}/pyclowder/pyclowder ${EXTRACTORS_HOME}/extractors-cv/ocr
sed -i -e "s#rabbitmqURL = .*#rabbitmqURL = '${RABBITMQ_URL}'#" ${EXTRACTORS_HOME}/extractors-cv/ocr/config.py
cp ${EXTRACTORS_HOME}/extractors-cv/ocr/clowder-ocr.conf /etc/init
chown -R clowder.users pyclowder
audio
apt-get -y install sox libsox-fmt-mp3
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/extractors-audio.git
ln -s ${EXTRACTORS_HOME}/pyclowder/pyclowder ${EXTRACTORS_HOME}/extractors-audio/preview/
sed -i -e "s#Binary = .*#Binary = '`which sox`'#" -e "s#rabbitmqURL = .*#rabbitmqURL = '${RABBITMQ_URL}'#" extractors-audio/preview/config.py
cp ${EXTRACTORS_HOME}/extractors-audio/preview/clowder-audio-preview.conf /etc/init
chown -R clowder.users extractors-audio
image
apt-get -y install imagemagick
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/extractors-image.git
ln -s ${EXTRACTORS_HOME}/pyclowder/pyclowder ${EXTRACTORS_HOME}/extractors-image/preview/
sed -i -e "s#imageBinary = .*#imageBinary = '`which convert`'#" -e "s#rabbitmqURL = .*#rabbitmqURL = '${RABBITMQ_URL}'#" extractors-image/preview/config.py
cp ${EXTRACTORS_HOME}/extractors-image/preview/clowder-image-preview.conf /etc/init
chown -R clowder.users extractors-image
apt-get -y install imagemagick
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/extractors-pdf.git
ln -s ${EXTRACTORS_HOME}/pyclowder/pyclowder /home/clowder/extractors-pdf/preview/
sed -i -e "s#Binary = .*#Binary = '`which convert`'#" -e "s#rabbitmqURL = .*#rabbitmqURL = '${RABBITMQ_URL}'#" extractors-pdf/preview/config.py
cp ${EXTRACTORS_HOME}/extractors-pdf/preview/clowder-pdf-preview.conf /etc/init
chown -R clowder.users extractors-pdf
video
apt-get -y install libav-tools
cd /home/clowder
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/extractors-video.git
ln -s /home/clowder/pyclowder/pyclowder /home/clowder/extractors-video/preview/
sed -i -e "s#Binary = .*#Binary = '`which convert`'#" -e "s#rabbitmqURL = .*#rabbitmqURL = '${RABBITMQ_URL}'#" extractors-video/preview/config.py
cp /home/clowder/extractors-video/preview/clowder-video-preview.conf /etc/init
chown -R clowder.users extractors-video
start extractors
cd /etc/init for x in clowder-*.conf; do start `basename $x .conf` done