...
Create and save extractor_info.json using any text editor in your source directory. This file contains the metadata about the extractor that you are creating. Please fill in the relevant details about the extractor in this file. This document follows the JSON-LD standard. A template extractor_info.json has been provided below for reference. As you can see, you can fill in the details like name, version, author, contributors, source code repository, docker image name, the data types on which the extractor will work, external services used, any dependent libraries, BibTex format citation to a list of publications that the extractor is referring to, etc. An example extractor_info.json can be found here:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32{"@context":"<context root URL>","name":"<extractor name>","version":"<version number>","description":"<extractor description>","author":"<first name> <last name> <<email address>>","contributors": ["<first name> <last name> <<email address>>","<first name> <last name> <<email address>>"],"contexts": [{"<metadata term 1>":"<URL definition of metadata term 1>","<metadata term 2>":"<URL definition of metadata term 2>"}],"repository": [{"repType":"git","repUrl":"<source code URL>"}],"process": {"file": ["<MIME type/subtype>","<MIME type/subtype>"]},"external_services": [],"dependencies": [],"bibtex": []}- Download the Docker Compose file from
- https://opensource.ncsa.illinois.edu/bitbucket/projects/CATS/repos/pyclowder2/raw/docker-compose.yml
You can also use curl command to download it from a terminal:
curl https://opensource.ncsa.illinois.edu/bitbucket/projects/CATS/repos/pyclowder2/raw/docker-compose.yml--output docker-compose.yml
- https://opensource.ncsa.illinois.edu/bitbucket/projects/CATS/repos/pyclowder2/raw/docker-compose.yml
Start up the Clowder services stack (Clowder, RabbitMQ, MongoDB, and ElasticSearch) by running the following command from the directory containing the downloaded docker-compose.yml file. This may take a few minutes when running for the first time:
docker-compose -p clowder upCreate and save a Dockerfile in your existing source code directory. This can be done using any text editor in your computer. The content of the Dockerfile needs to be the following, where you should replace my_python_program.py and my_main_function with their actual names:
FROM clowder/extractors-simple-extractor:onbuildENV EXTRACTION_FUNC="my_main_function"ENV EXTRACTION_MODULE="my_python_program"- If there are any Python or Linux packages that are required by your code, please add them to two files named requirements.txt and packages.apt in the source code directory. Each package entry should be added to a separate line in these files.
Now, create the Docker image for your extractor using the command below. Please note that there is a dot (.) at the end of the command. You will need to open a terminal client and change to your Dockerfile directory using the cd command before running the command below (this will also install the Python packages from requirements.txt and Linux apt-get packages from packages.apt):
docker build -t my_extractor .In the terminal, you should be able to see the logs of the services that are part of the Clowder stack.
From another terminal window, you can now run your extractor using the following command:
docker run -t -i --rm--network clowder_clowder my_extractorYou should be able to see the logs related to the starting extractor in this terminal window.
- You can always test your python code before wrapping it as an extractor. To test your built extractor, you will need to sign up and create an account in your local Clowder instance. Please follow the steps below:
- Open your web browser and go to http://<ip_address>:9000/signup, where <ip_address> needs to be replaced by your computer’s IP address. You can run ifconfig (Mac/Linux) or ipconfig (Windows) command from a terminal window to find your computer’s IP address.
- Once you are in the sign up page, please create an account using your email address as shown in figure above. Click on the "Create Account" after you enter your email address.
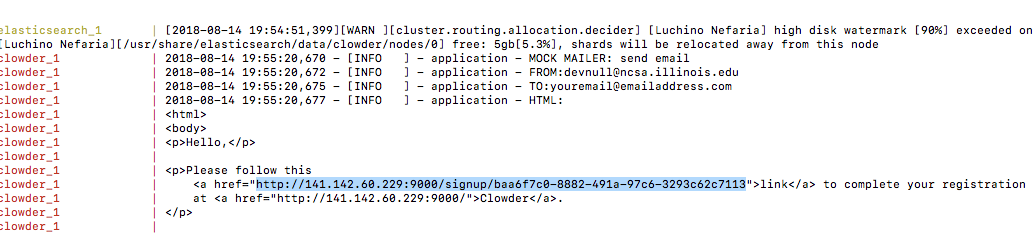
- Now, you need go back to the terminal where you launched Clowder services stack and check the log (for concise presentation, the below screenshot has been partially cropped on left side). You will see a URL (highlighted) of the Sign Up form. Please go to that URL from your web browser. Please note that you are just signing up for an account in your local Clowder instance and the information you provide will remain local to your computer.
- Once you are in the Clowder’s Sign Up page, please fill in the form and click the "Create Account" button.
- Now you can login to your local Clowder instance your email address and password that you set up during the signup process. After you login, you can create a dataset and upload a file for testing. After the extractor processes your file, you will be able to see the generated metadata in the Clowder file page. You will also see some relevant messages in the terminal window where the extractor is running.
- Open your web browser and go to http://<ip_address>:9000/signup, where <ip_address> needs to be replaced by your computer’s IP address. You can run ifconfig (Mac/Linux) or ipconfig (Windows) command from a terminal window to find your computer’s IP address.
To stop the Clowder services stack, you will need to open a terminal client and change to your Clowder docker-compose.yml directory using the cd command before running the command below:
docker-compose -p clowder down- To stop the extractor, you will need to go to the terminal where the extractor is running and press Control + C from keyboard.


...