...
import pyclowderfrom pyclowder.extractors import Extractorimport pyclowder.files
...etc.
Running a sample extractor
Now that we have our necessary dependencies, we can try running a simple extractor to make sure we've installed things correctly. The wordcount extractor is included with pyClowder 2 and will add metadata to text files when they are uploaded to Clowder.
- Go to
/pyclowder2/sample-extractors/wordcount/ - Run the extractor
- python wordcount.py is basic example
- If you're running Docker, you'll need to specify the correct RabbitMQ URL because Docker is not localhost:
python wordcount.py --rabbitmqURI amqp://guest:guest@<dockerIP>/%2f - You can use
python wordcount.py -hto get other commandline options.
- When the extractor reports "
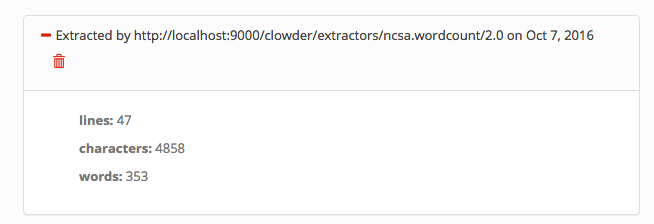
Starting to listen for messages"you are ready. - Upload a .txt file into Clowder and verify the extractor triggers and metadata is added to the file, e.g.:
Writing an extractor
...
Extractor basics
When certain events occur in Clowder, such as a new file being added to a dataset, messages are generated and sent to RabbitMQ. These messages describe the type of event, the ID of the file/dataset in question, the MIME type of the file, and other information.
Extractors are configured to listen to RabbitMQ for particular types of messages. For example, an extractor can listen for any file being added to a dataset, or for specifically image files to be added to a dataset. Clowder event types below describes some of the available messages. RabbitMQ knows how to route messages coming from Clowder to any extractors listening for messages with that signature, at which point the extractor can examine the message and decide whether to proceed in processing the file/dataset/etc.
Clowder event types
Extractors use the RabbitMQ message bus to communicate with Clowder instances. Queues are created for each extractor, and the queue bindings filter the types of Clowder event messages the extractor is notified about. The following non-exhaustive list of events exist in Clowder (messages begin with an asterisk because the exchange name is not required to be 'clowder'):
| message type | trigger event | message payload | examples |
|---|---|---|---|
| *.file.# | when any file is uploaded |
| clowder.file.image.png clowder.file.text.csv clowder.file.application.json |
*.file.image.# *.file.text.# ... | when any file of the given MIME type is uploaded (this is just a more specific matching) |
| see above |
| *.dataset.file.added | when a file is added to a dataset |
| clowder.dataset.file.added |
| *.dataset.file.removed | when a file is removed from a dataset |
| clowder.dataset.file.removed |
| *.metadata.added | when metadata is added to a file or dataset |
| clowder.metadata.added |
| *.metadata.removed | when metadata is removed from a file or dataset |
| clowder.metadata.removed |
Typical extractor structure
In a pyClowder 2 context, extractor scripts will have 3 parts:
main()will set up the connection with RabbitMQ and begin listening for messages. This typically will not change across extractors.check_message(parameters)receives the message from RabbitMQ and includes information about the message in the parameters argument. Extractors can count the number of files, look for particular file extensions, check metadata and so on.- Return 'true' or 'download' to download the file(s) process with process_message (below)
- Return 'bypass' to process with process_message, but skip downloading the file automatically
- Return 'false' or 'skip' to decline processing the file.
process_message(parameters)receives the message and, if specified in check_message(), the file(s) themselves. Here the actual extractor code is called on the files. Outputs can also be uploaded back to Clowder as files and/or metadata, for example.
In addition to the extractor script itself:
extractor_info.jsoncontains some metadata about the extractor for registration and documentation.- Many extractors will also include a Dockerfile for creating docker images of the extractor.
Running a sample extractor
Now that we have our necessary dependencies, we can try running a simple extractor to make sure we've installed things correctly. The wordcount extractor is included with pyClowder 2 and will add metadata to text files when they are uploaded to Clowder.
- Go to
/pyclowder2/sample-extractors/wordcount/ - Run the extractor
- python wordcount.py is basic example
- If you're running Docker, you'll need to specify the correct RabbitMQ URL because Docker is not localhost:
python wordcount.py --rabbitmqURI amqp://guest:guest@<dockerIP>/%2f - You can use
python wordcount.py -hto get other commandline options.
- When the extractor reports "
Starting to listen for messages"you are ready. - Upload a .txt file into Clowder
- Create > Datasets
- Enter a name for the dataset and click Create
- Select Files > Upload
- Verify the extractor triggers and metadata is added to the file, e.g.:
You'll be able to see some activity in the console where you launched the extractor if done correctly.
Writing an extractor
common requirements
| Code Block | ||
|---|---|---|
| ||
sudo -s
export RABBITMQ_URL="amqp://guest:guest@localhost:5672/%2F"
export EXTRACTORS_HOME="/home/clowder"
apt-get -y install git python-pip
pip install pika requests
cd ${EXTRACTORS_HOME}
git clone https://opensource.ncsa.illinois.edu/stash/scm/cats/pyclowder.git
chown -R clowder.users pyclowder |
...