...
BD-base runs the necessary dockerized Brown Dog Data Transformation Service components (Clowder, Polyglot, Fence, RabbitMQ, MongoDB, Redis, an example extractor, an example converter, and the BD CLI) allowing a developer to get up and running more quickly as they create and debug new extractors/converters. You can get the BD-base by cloning the git repo:
...
The BD-base script will split your terminal into panes and start each of the services needed for the Brown Dog DTS. This provides a useful and convenient way to view the logs of running services in panes.
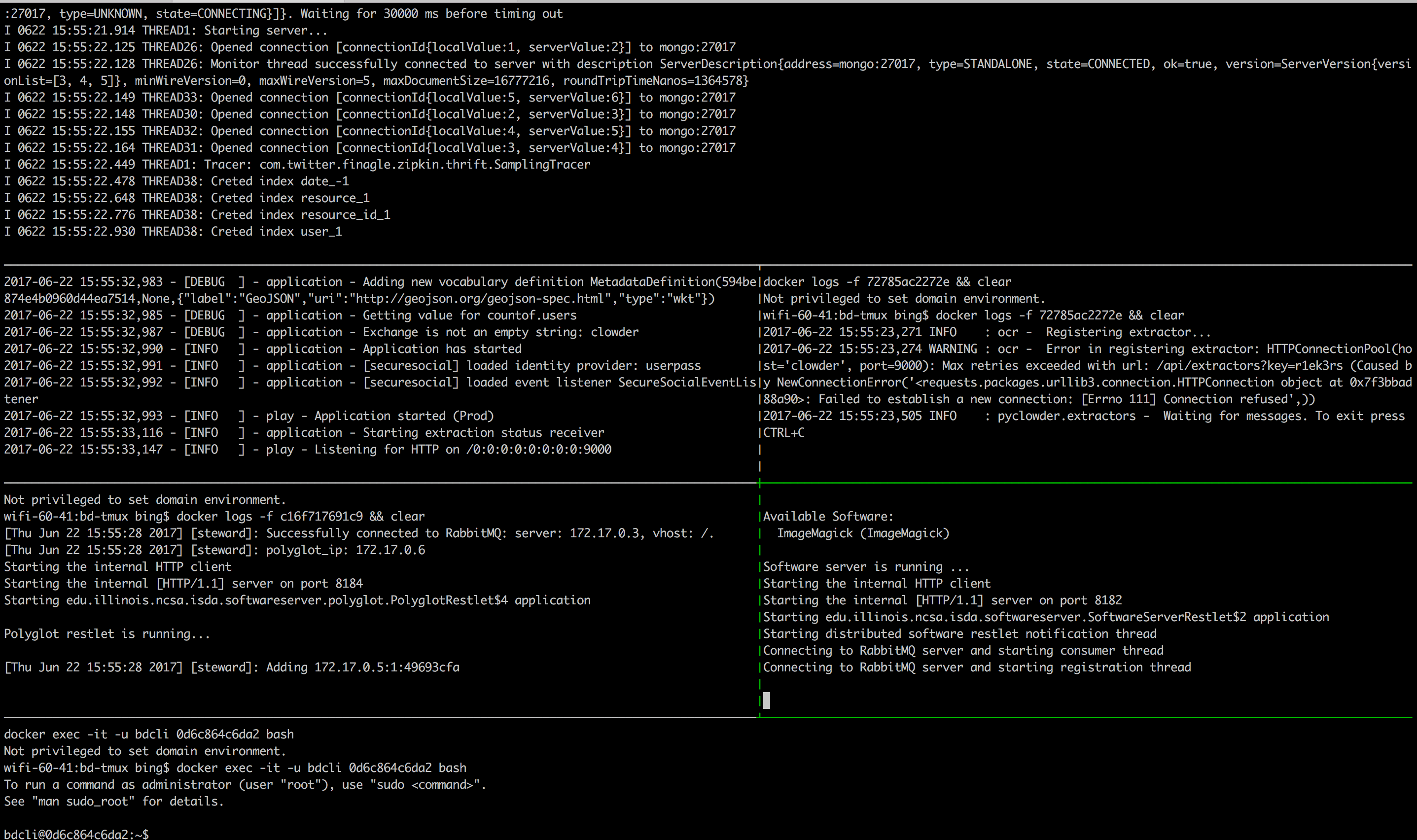
Users can switch between panes using Tmux commands. The panes are as follows: Fence (top), Clowder (middle-left), example extractor (middle-right), Polyglot (middle-left), example convert (middle-right), and the BD CLI (bottom). Users In the bottom pane, users can run BD-CLI commands to interact with the Brown Dog Data Transformation Service (username: bd, password: browndog):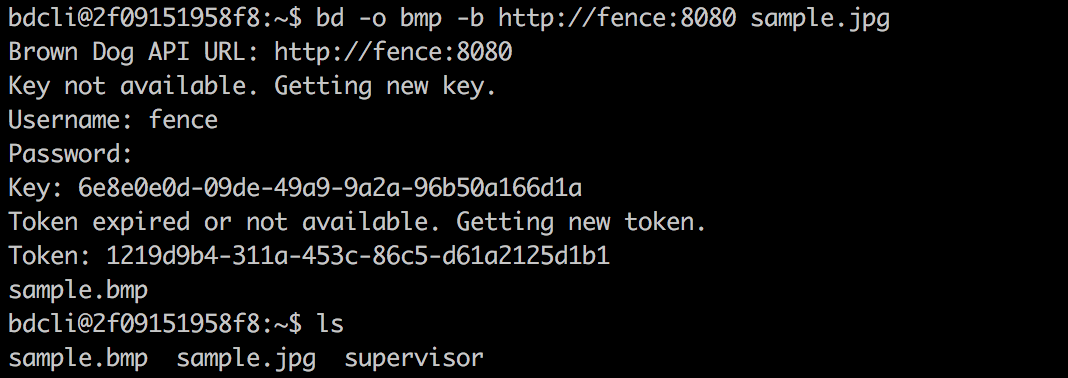
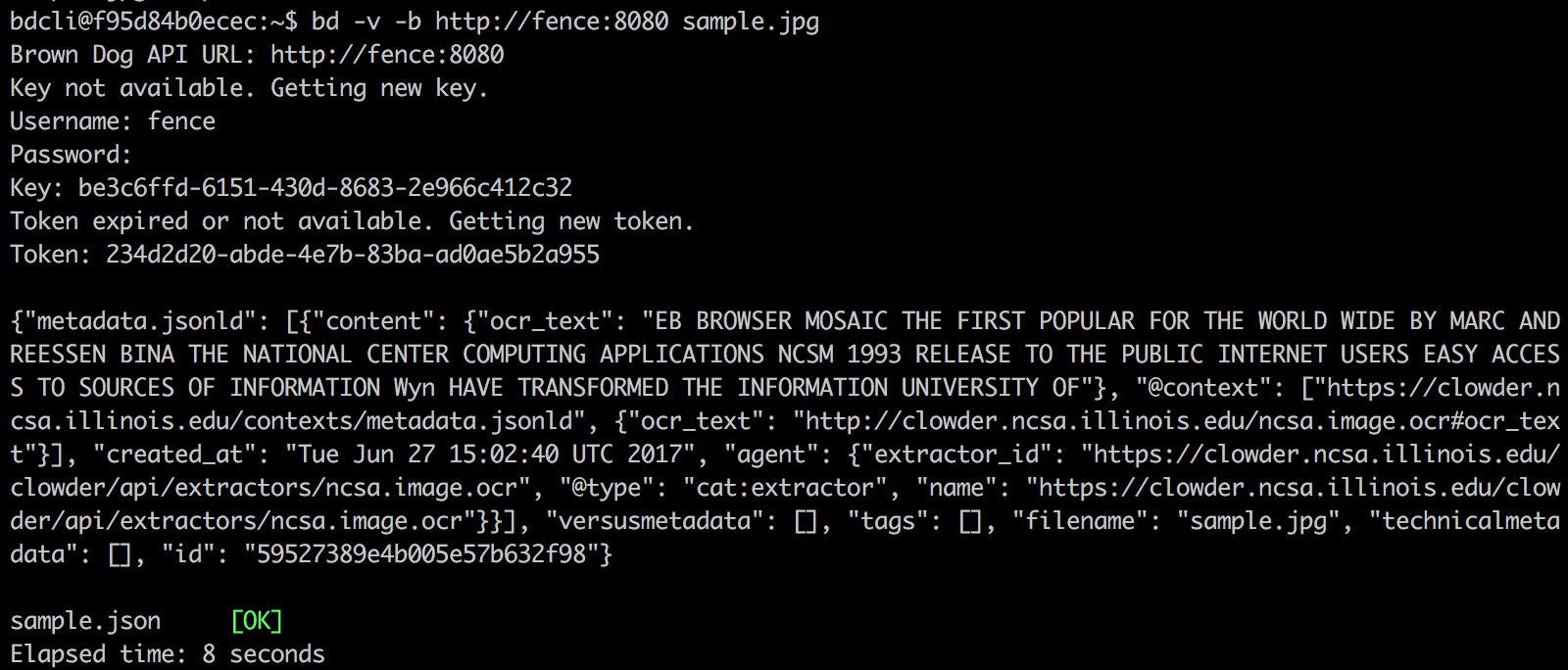
CTRL-b <arrow key> will navigate panes.
Exit the bd-base session by typing CTRL-b then :kill-session.
NOTE: There is a .tmux.conf file included in bd-base. If you copy this file into your home directory before starting a bd-base session you will be able to navigate panes via the mouse and end the session by typing CTRL-b then CTRL-c.
Extractors
Here we described describe the process for taking a working piece of code and deploying it as a Brown Dog extractor. It For simplicity, it is assumed that the method can be invoked from a single call. In this example, we are using the python extractor wrapper and will invoke a python function. In a very similar fashion, a method developed in a language other than python can be invoked using subprocess.
...
A few assumptions are that you have a tool that extracts some kind of metadata from a file or dataset and that you have installed Python, Git, and Docker as well as any other specific software needed by your extractor (if any) on your computer.
...
Install pyClowder2, which is a Python library that helps to easily communicate with Clowder - the backend services service of Brown Dog which handles extractions. The advantage of using this library is that it manages all communications with Clowder and RabbitMQ (the distributed messaging bus) and the developer doesn't have to take care of such tasks. Needless to say, an extractor can also be written in native Python without the use of pyClowder2, but it would be more time consuming.could be more
| Code Block | ||
|---|---|---|
| ||
pip install --upgrade pip pip install -r https://opensource.ncsa.illinois.edu/bitbucket/projects/CATS/repos/pyclowder2/raw/requirements.txt git+https://opensource.ncsa.illinois.edu/stashbitbucket/scm/cats/pyclowderpyclowder2.git |
2. Get Your Code Together
We have developed a template extractor written in Python. It is a simple wordcount word count extractor that counts lines, words, and characters in a text file. Clone the template extractor and rename the directory to an appropriate name that reflects the purpose of your extractor.
...
Make changes to extractors.py (main program). Consider the process_file method as the main method of an extractor and accordingly it needs to contain the main logic. You can call other methods in your python code from this method after importing necessary modules into this file.
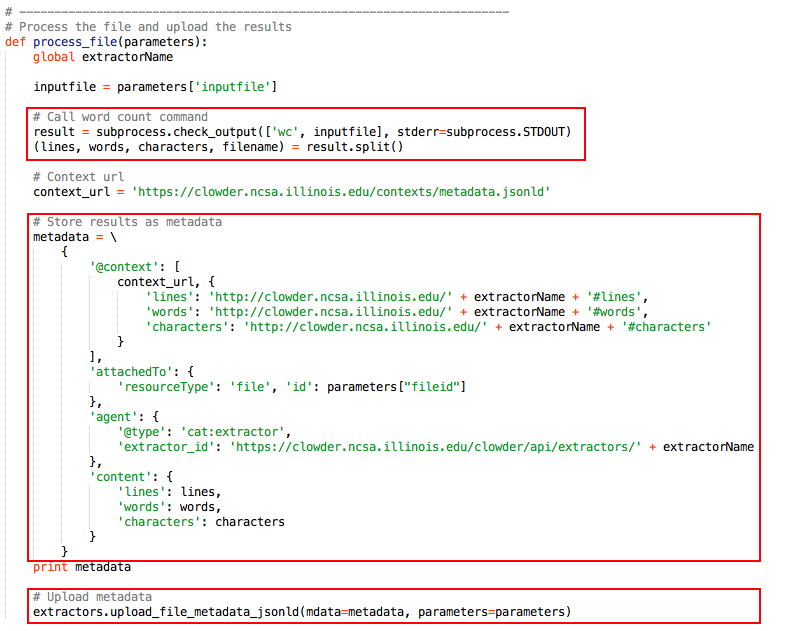
3.
...
Edit extractor
...
_info.json
This file contains information about the extractor in JSON-LD format. Update all relevant fields as needed.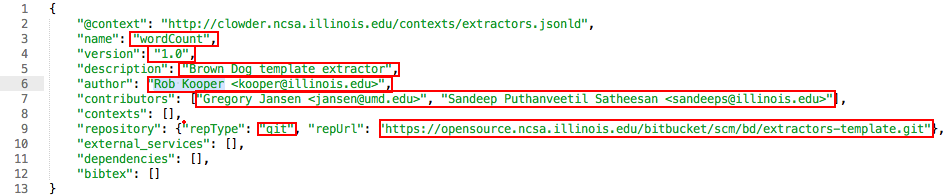
4. Configuration Parameters
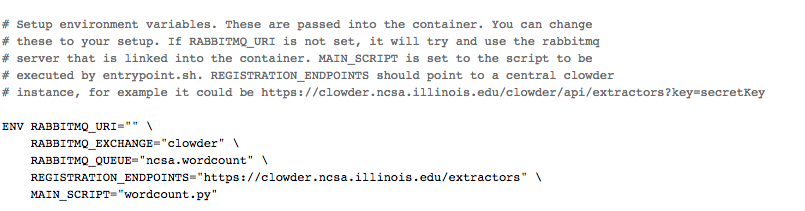
Extractors obtain the configuration details required to connect to RabbitMQ, Clowder, etc., either from command-line arguments or environment variables. If you look at the Dockerfile inside the termplate extractor directory you can see some of the environment variables being set. For the purpose of running your extractor using BD Development Base, you DO NOT have to change anything.
Note: The remaining part of this section is relevant ONLY if you want to run your extractor against another production instance at some other location. Otherwise, you can skip and continue reading the next section.
If you are planning to run your extractor using Docker, you will need to modify the Dockerfile to set the environment variables as required.
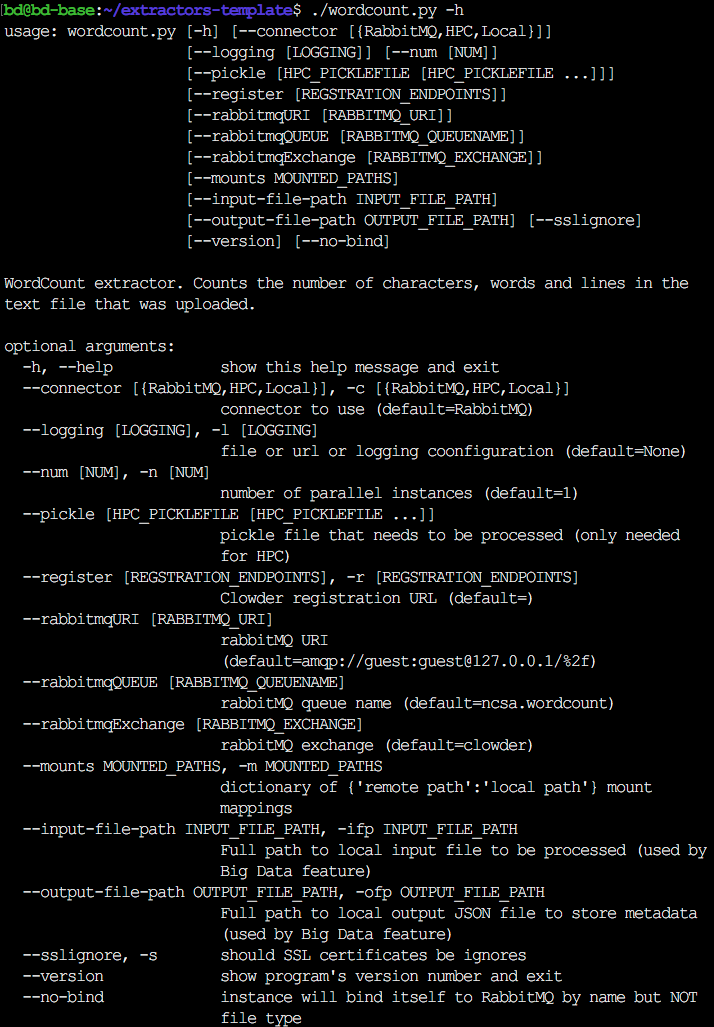
Otherwise, if you run your extractor as a standalone program (outside of Docker), you will need to set the relevant command-line arguments. You can get a list of these parameters by running your extractor with the help option (-h, --help).
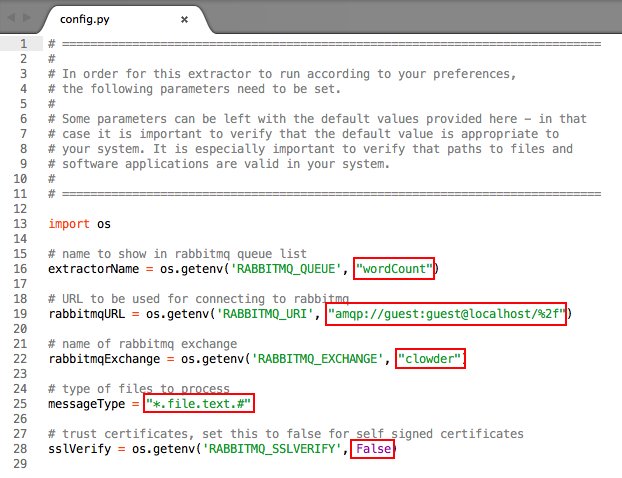
Change the rabbitmq queue name - in this case replace "wordCount" with an appropriate name for your extractor
- Change the messageType field to reflect the MIME type(s) of the file for which you are writing the extractor
- Update other fields like rabbitmqURL, rabbitmqExchange, sslVerify, to include
- If your extractor needs other custom parameters, they need to be added to config.py
4. Edit extractor.info.json
This file contains metadata about the extractor in JSON-LD format. Update all relevant fields as needed.
5. Edit the Dockerfile
...
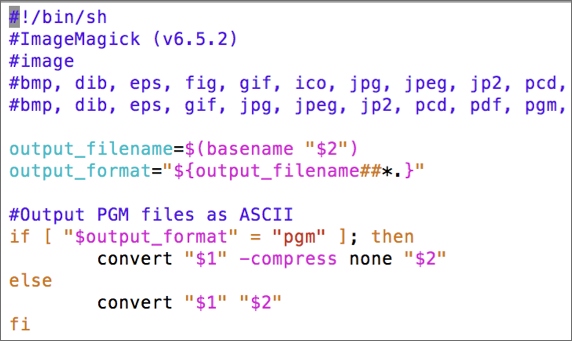
This script will be used by the Software Server to run the tool and carry out any requested conversions. The example script ImageMagick_convert.sh that uses ImageMagick tool to convert images between different formats is shown below. The conversion script follows a specific header and is written as comments:
- First line is the shebang line
- Second line contains the name of the converter followed by the version (if any)
- Third line refers to the type of the data that it can convert
- Fourth line contains a comma-separated list of the input file formats accepted by this converter
- Fifth line contains a comma-separated list of the output file formats that this converter can generate
- This is followed by the actual code that does conversion.
2. Edit the Dockerfile
...