Motivation
We currently track extractor messages by resource - for a dataset or file, the user can view a list of Extractor events that were associated with that file.
The list of events is further categorized by extractor, but this can still be inadequate for tracking multiple jobs running on the same extractor.
The problem is exacerbated exponentially if multiple replicas or threads are running for a particular extractor - this means that 2 jobs can simultaneously be sending updates for the same extractor + file or dataset combination, and makes it impossible to determine which jobs sent which updates.
In addition to resolving the problem stated above, expanding extractor job tracking would also allow extractor developers to better debug and analyze their extractor jobs, or to determine if there are performance enhancements that could be made.
Changes Proposed
pyclowder
pyClowder may need minor updates to send more information regarding a specific job. Alongside the user, resource (e.g. dataset or file), and extractor name, pyClowder should also attach a unique identifier (e.g. UUID) to related job messages. That is, when an extractor begins working on a new item from the queue, it should assign a unique identifier to that workload that is unique to each run of the desired extractor.
This way, we can easily create a UI that can filter and sort through these events without making major modifications to the UI and without taking a large performance hit in the frontend.
API
The API changes proposed should be fairly minimal, as we are simply extending the existing Extraction API to account for the new identifier that will need to be added to pyClowder.
UI
The UI takes on the brunt of the changes here.
Displaying extractor events currently looks as follows:
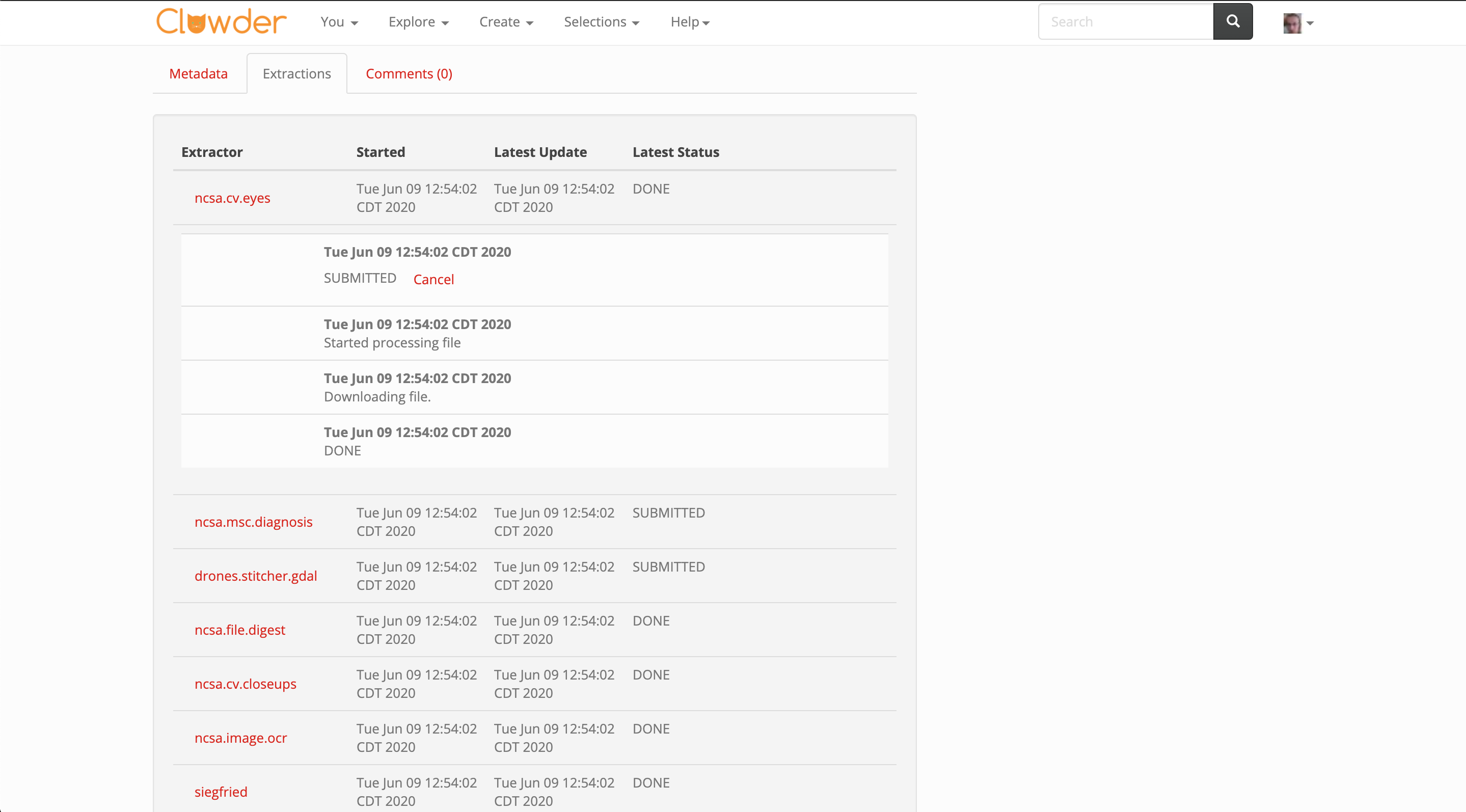
We offer a tab that lists all extractors that have run on the file or dataset.
The user can click an extractor to expand a subsection containing individual events from that extractor.
We propose altering the UI with the following changes:
- Categorize further based on the unique identifier for each job - this allows user
- For finished extractor jobs (?), show the elapsed time it took to complete the job
The final product might look something like this:

Open Questions
- What do we do about past extractions/jobs that are missing this identifier? Should we preserve the existing display in the UI for this purpose?